据Google官方博客报道,谷歌通过一系列实验证明,微软通过IE浏览器、必应工具栏等手段监测用户的谷歌搜索行为,并借用这些信息改进微软必应(Bing)搜索结果,谷歌因而指控微软必应搜索引擎抄袭谷歌的网络搜索结果。
谷歌研究员阿密特·辛格哈尔(Amit Singhal)在这篇博文中指出,谷歌注意到,在用户输入拼写错误的情况下,必应搜索结果与谷歌搜索结果显示的网站惊人地相似。
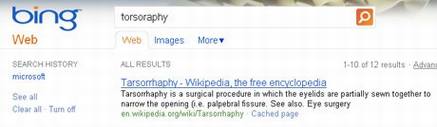
最开始的怀疑来自tarsorrhaphy这个单词,tarsorrhaphy是一种罕见的眼皮手术,当用户输入“torsoraphy”进行搜索的时候,谷歌会自动将用户的拼写更正为“tarsorrhaphy”,进而提供相关的搜索结果,其中排名最靠前的是维基百科对于这个医学术语词条的解释。
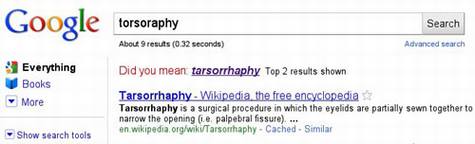
早期用户通过必应搜索“torsoraphy”,因为拼写错误,并没有返回搜索结果,但是后来谷歌发现,必应之后开始在没有提出拼写更正建议的情况下,对这个单词返回搜索结果,排名最靠前的同样是维基百科对“tarsorrhaphy”这个词条的解释。这种现象引发了谷歌的怀疑,微软必应搜索引擎为什么没有纠正用户的拼写错误,却返回了正确的查询结果。
为了证实微软必应抄袭谷歌的搜索结果的怀疑,谷歌启动了一系列实验。谷歌有史以来首次撰写了一些一次性代码,允许对部分特定的词条手工排列搜索结果页面。之后,谷歌编写了100余词条(指纹陷阱),并称之为“人造搜索”。
2010年12月17日,大约20名谷歌工程师按照要求,在家中通过笔记本电脑上网搜索,使用的是IE浏览器,同时启动了“推荐网站”和必应工具栏。他们输入人造词条进行搜索,并点击搜索结果排名靠前的页面。到12月31日,必应搜索出现了同样的搜索结果。
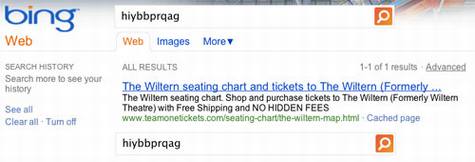
例如人造词条“hiybbprqag”等预先设定的关键词时,由于单词十分古怪,通常并不会得到太多有用的搜索结果,最初在谷歌和必应都没有任何搜索结果。但谷歌开始实验之后,搜索结果页面的顶端会显示某些预先人工设定的、与这些怪异的关键词并无关联的结果,如大型企业的网站等。假如用户使用其他搜索引擎,该代码就不会被激活,从而无法得到与谷歌相同的搜索结果。
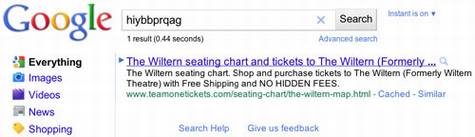
两周之后,必应搜索“hiybbprqag”也出现了同样的搜索结果。
谷歌的实验表明,IE浏览器在默认设置下,将抓取用户的浏览数据,用于改善必应的搜索结果。而微软也已经证实,这一功能确实会收集部分用户浏览网站的数据。此外,如果用户安装了必应工具栏,那么它的默认设置将抓取用户信息,以改进用户的搜索体验。
阿密特在博文的最后指出,谷歌坚信创新,并为谷歌的搜索质量感到自豪,为了用户最佳的搜索体验,谷歌投入了大量的研发来改善搜索算法。谷歌期待着与真正创新的搜索算法竞争,无论是必应还是其他搜索引擎,而不是从竞争对手那里复制搜索结果。至于谷歌为什么要针对微软发这篇文章,答案很简单,谷歌希望微软必应停止这种抄袭的做法。